
Following up on my post The Future of Virtual Networking from VMworld – Part 1 (read that before starting this one), I’m going to continue rambling on about some of the awesome future networking ideas floating around during VMworld.
Disclaimer: this post is also based on public roadmap information divulged by VMware and can be subject to change. Also, some of this is my interpretation of the features.
Distributed Load Balancing
With traditional load balancing, network traffic goes through an appliance (physical or virtual) before it connects to the actual target (load balanced server). This is set up this way because the clients using the load balanced service need to connect to a certain IP address to consume the load balanced service. This IP is usually a virtual IP address living on two (or more) load balancer appliances. These load balancer appliances make sure that virtual IP is high available and they route the traffic to the load balanced servers on a load balancing hashing method (round-robin, least-connection, etc). VMware has implemented L4 to L7 load balancing inside the NSX Edge Services Gateway and you can hook up third party vendors like F5 to create an advanced load balancing solution.
With Distributed Load Balancing (DLB), the point where the network traffic comes in, is distributed towards the ESXi kernel (just like the Distributed Router function). This means the traffic does not need to go through a NSX Edge anymore. This basically lifts the bandwidth limitation for load balancing, as the bandwidth of a NSX Edge is limited to its virtual interfaces. Distributed Load Balancing looks like this:
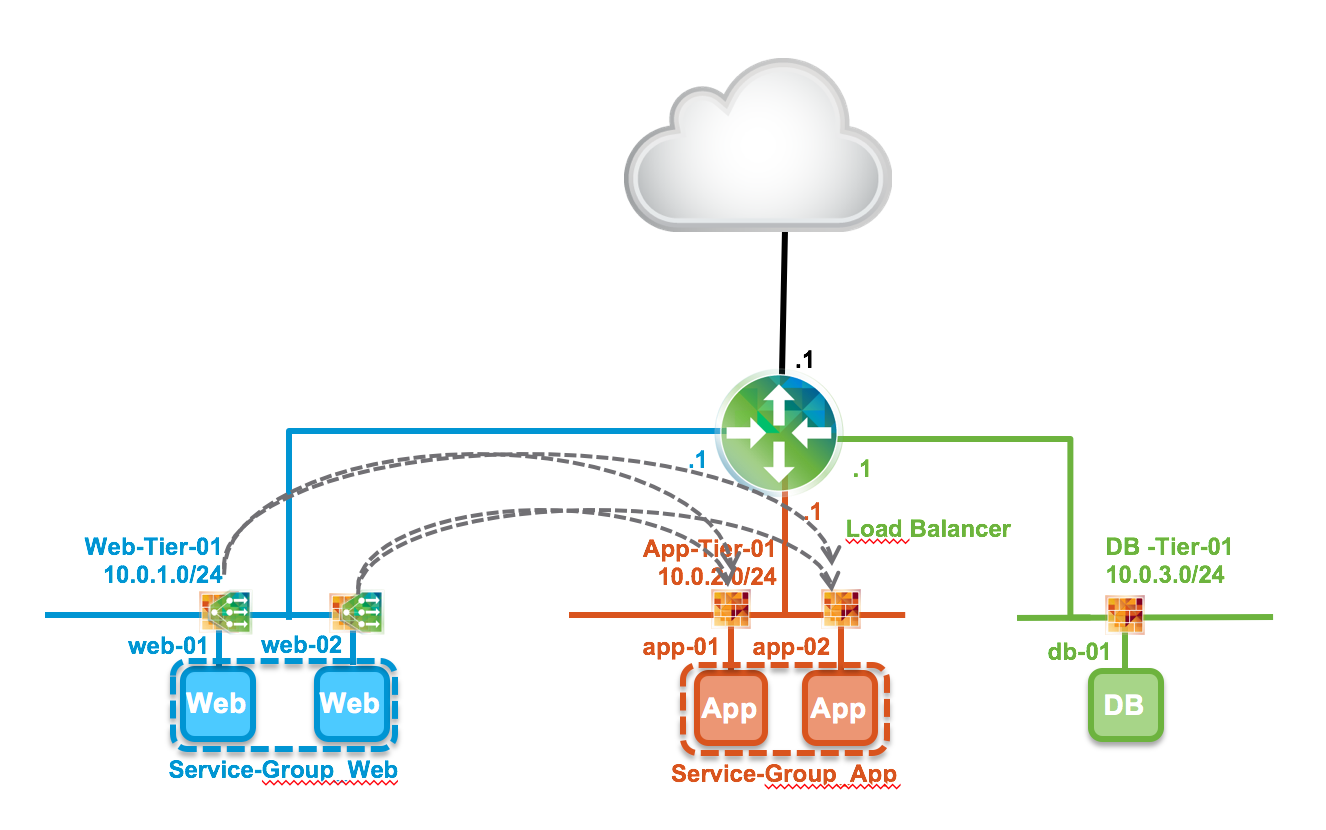
Just like the Distributed Firewall, this Distributed Load Balancer is injected into the ESXi kernel so it can be put into effect on the vNIC level of a virtual machine. The ESXi kernel then starts to look for traffic heading to load balanced virtual IP and redirect that accordingly to the IP addresses of the real servers, taking a global load distribution table into account. I assume this distribution table will live on the NSX Controllers.
For some nitty gritty details, here’s a screenshot of a firewall rule inside an ESXi server generated by Distributed Load Balancing;

Distributed Network Encryption
If executed properly, this could be a cool feature. Encryption is usually only used between certain locations and not inside the locations themselves, encrypting the traffic between datacenters, but not inside the datacenter itself. While multi tenancy is becoming a familiar habit for datacenters, it makes sense to start encrypting the traffic inside your datacenter as well. It currently does not make practical sense to do so, due to the major size of configurations needed to realise this and the upkeep it would take to keep it up and running. Plus, wish your operations department luck..visibility tools? Unlikely.
If you incorporate it into the virtualisation layer, it could be similar to VXLAN tunnels, where the ESXi hosts make sure there’s an encrypted network tunnel between all your ESXi hosts (a mesh) and you would be able to cross a checkbox on a virtual machine, which would make the ESXi host push the traffic towards the encrypted tunnels, instead of the unencrypted tunnels. Better yet, create dynamic Service Groups which enable that checkbox when the virtual machine has a certain name or security tag.
VMware has said to be partnering with Intel and their Intel-based crypto acceleration processing to offload this encryption mechanism to the physical hardware, which would save CPU cycles on the ESXi host (as that’s the most utilised resource with encryption) and I’m very curious about the resources it would take to execute this on a large scale. I’ve tried to get some information, but VMware seems to be in the R&D stage on this.
If they succeed in implementing this for large scale deployments, there are a lot of use cases Distributed Network Encryption could be very beneficial; mitigate man-in-the-middle attacks inside the datacenter, easy compliancy to regulatory demands (maybe this feature would even generate new regulatory demands?), a very easy way to encrypt all traffic flowing between a twin datacenter setup (without having to use encrypted [D|C]WDM equipment), you could probably think of a few more. 😉
Extending Virtual Networks to the Cloud
The Hybrid Cloud is becoming a fairly commonly used strategy, where some of the virtual infrastructure resides locally and some of the virtual infrastructure resides in a public cloud (AWS, Azure, etc). Currently, most networks are bridged together with either a VPN or a Direct Connect line to the local datacenter. This results into a dual set of network properties to manage with separate security policies, separate routing configuration, possibly home made scripting to sync policies across the two locations, basically a pain to manage.
VMware is tying NSX into the clouds, starting with Amazon Web Services. This first step is already pretty far in development, as VMware has demo’d this in the VMworld keynotes and sessions around it.
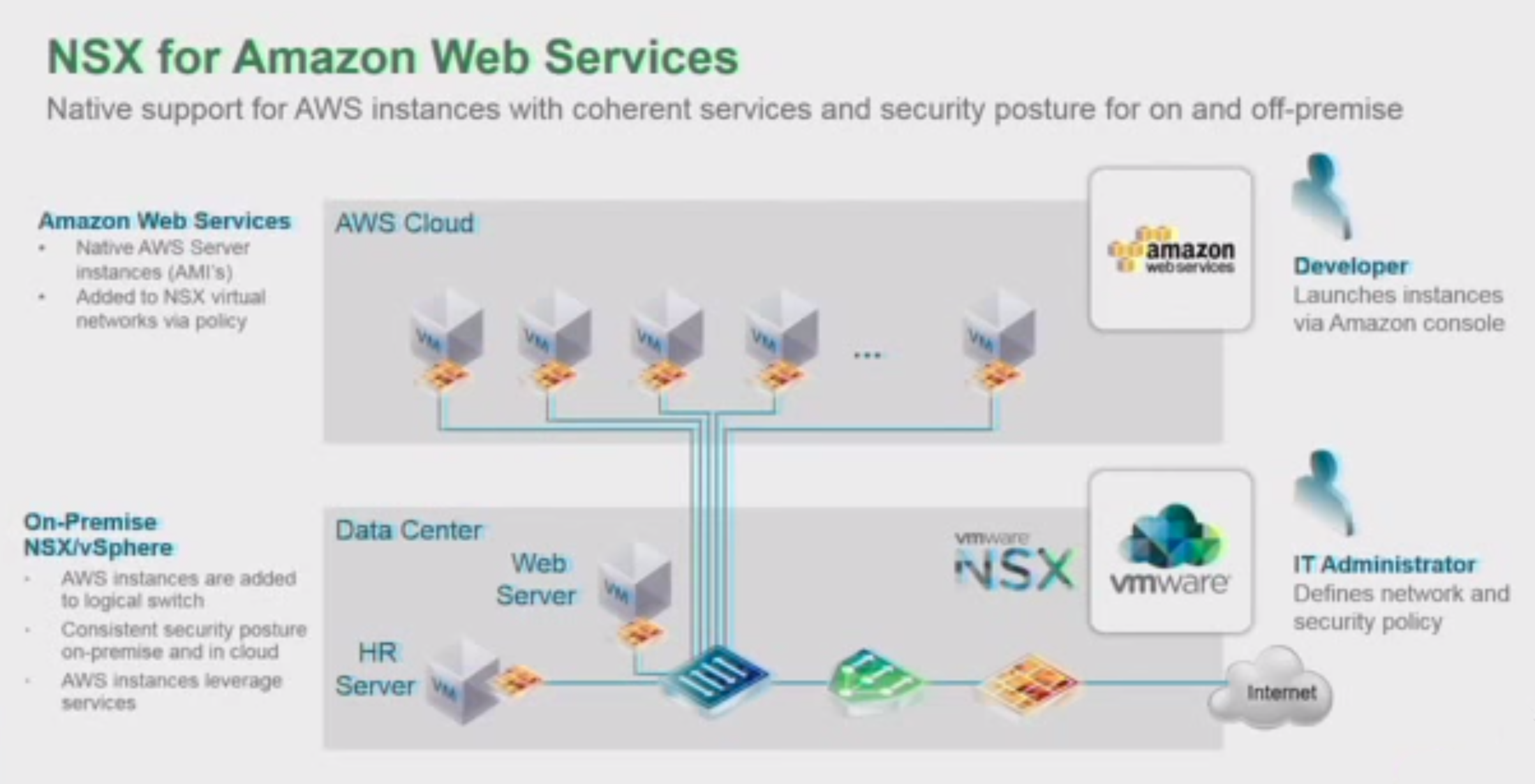
The way this is accomplished is very portable. Basically they created a Amazon Machine Image (AMI) with the vSwitch code, with the logical switch, state-full firewall, load balancing, all NSX features, attached to it. When you deploy instances of this AMI on AWS, the vSwitch code on the instance registers with the NSX Manager on startup to request the configurations (security policies, logical switch, load balancing, etc) and setup a tunnel to join the local datacenter network.
Considering this is an modulair type of addition to an existing image format on AWS, all that is needed to port this module to other formats (i.e. Azure, Google Cloud or Hyper-V, Docker, KVM, Xen, CloundFoundry) is the native language translation between the vSwitch and hypervisor, so I expect other clouds and hypervisors to be added fairly quickly once NSX for Amazon Web Services is publicly released.
Containers and Security
Currently, containers can pose a security risk. Different containerised applications running on the same container host, being able to access one and other without restriction by default. When adding firewalling capabilities to a container host you’ll be managing the security policies on a per container host basis and there is likely no centralised overview. With “Containers with VMware NSX” – VMware is adding the same capabilities of regular virtual machines to the networking of containers.
With basically the same technique used for NSX for AWS, VMware created a module inside Docker, which contains the vSwitch code and has the ability to report and connect to the NSX Manager. After reporting to the NSX Manager, it receives the proper security policies and other configuration needed to secure the different containers on the host.
This seems like a simple feature, but this adds the scala of features inside NSX to containers, creating the possibility for easy micro segmentation of containers, the ability to put alerts on suspicious network traffic going to or from containers and most of all, creates a centralised overview of all containers with their respective security policies.

GENEVE Overlay Protocol
VXLAN, NVGRE and Stateless Transport Tunneling (STT) are all overlay encapsulation protocols which can be used to create virtual networks. VMware has standardised on VXLAN for vSphere environments and STT for Multi-Hypervisor environments. This works fine, but the main problem of these protocols is that they have a defined format and that they are not really extensible. With all the advances in network virtualisation, these protocols have been slightly modified by vendors to keep up with these advances. This creates standard deviations and incompatibility all around.
It makes sense for an extensible network overlay protocol to be created which can keep up with the advances in network virtualisation and VMware, Microsoft, RedHat, Cumulus, Arista and Intel are co-authoring a new protocol called Generic Network Virtualisation Encapsulation, or GENEVE.

The header format of GENEVE looks a lot like VXLAN, with the addition of an extensible option field. This field can be used to add new network capabilities whenever a vendor comes up with them, without breaking the standard. This means a multi vendor environment (physical and virtual) will continue to function if one vendor adds new features. Imagine what it could mean for security if you could actually put the user or application identifier inside the network packet itself, instead of deducting where it came from with Active Directory and IP data, as we do now.
With VXLAN support in network equipment maturing (NIC offloading, switches starting to support it properly in combination with hypervisors), why would you need another protocol that needs to go through the same process? Basically the idea is to never have to go through that process again after GENEVE matures, end a protocol sprawl and work towards a world where all vendor equipment and software can link with each other to create a vast ecosystem of interoperable network systems.
It will be a while before you’ll see it in production environments though, VMwares first step will probably be to implement GENEVE for the tunnelling between ESXi hosts and use the extensibility in vSphere to support the development of new network virtualisation features inside vSphere.
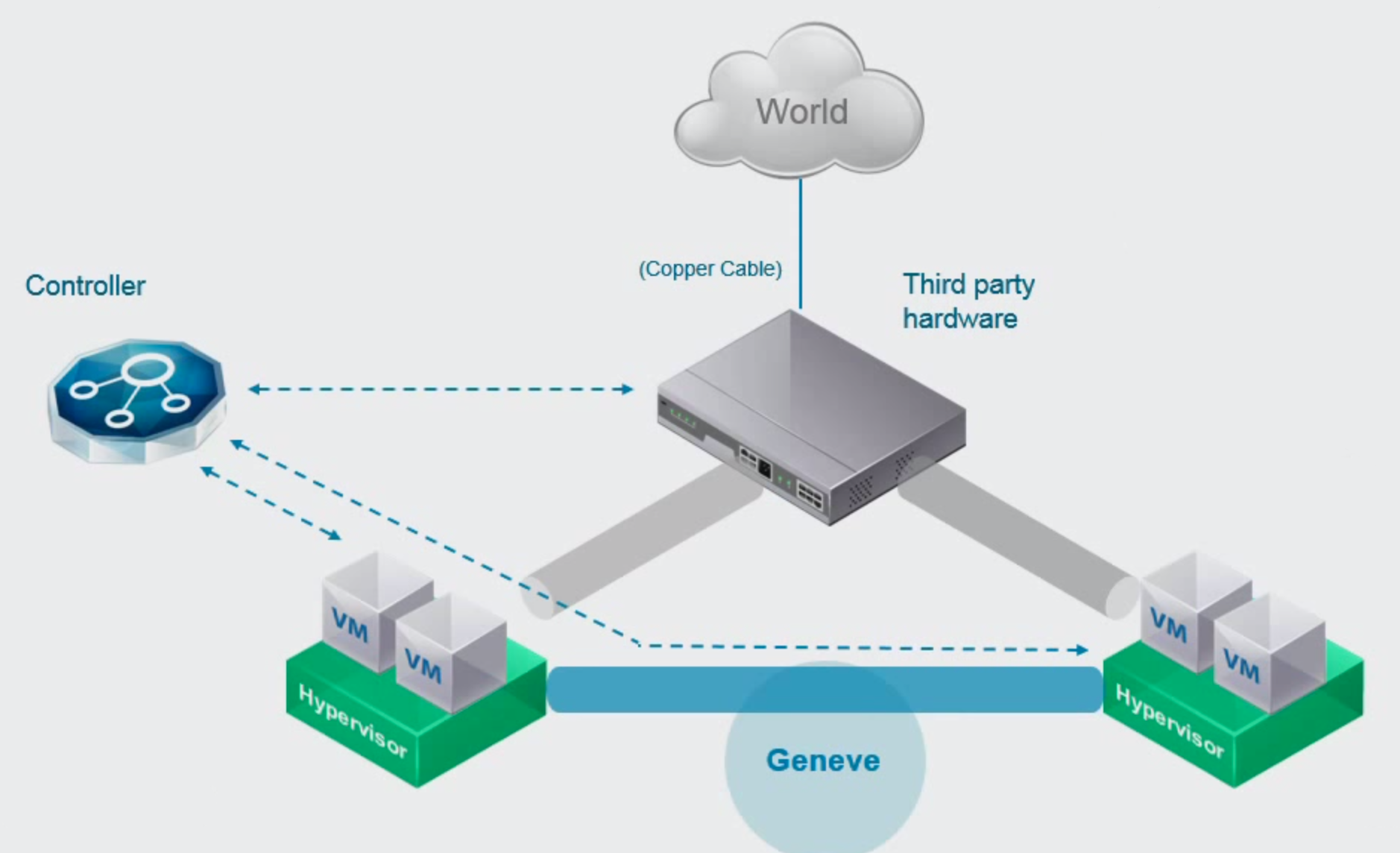
After a while, we’ll see adoption by switch vendors, making their physical switches compatible with GENEVE and we’ll start towards the virtual and physical network mesh, which we now see with VXLAN and OVSDB implementations.
You can find the IETF proposal for GENEVE here.
Conclusion
We’re in exciting times in the networking industry when it comes to blending the virtual and physical networks together and all the exciting features and flexibility that that blend brings. I’m looking forward to watch this transformation and all the goodness is still to come.
Alright, that’s it for my VMworld summary. As always it was a fun event with shattering eye-openers for me and I hope you liked these summaries. Rest assured, I’ll be going back to regular posts which won’t be so long and dreary. 🙂
Leave a Reply